AWS Machine Learning Blog
Category: Best Practices

Accelerate your generative AI distributed training workloads with the NVIDIA NeMo Framework on Amazon EKS
In today’s rapidly evolving landscape of artificial intelligence (AI), training large language models (LLMs) poses significant challenges. These models often require enormous computational resources and sophisticated infrastructure to handle the vast amounts of data and complex algorithms involved. Without a structured framework, the process can become prohibitively time-consuming, costly, and complex. Enterprises struggle with managing […]

Prompt engineering techniques and best practices: Learn by doing with Anthropic’s Claude 3 on Amazon Bedrock
You have likely already had the opportunity to interact with generative artificial intelligence (AI) tools (such as virtual assistants and chatbot applications) and noticed that you don’t always get the answer you are looking for, and that achieving it may not be straightforward. Large language models (LLMs), the models behind the generative AI revolution, receive […]

Accelerated PyTorch inference with torch.compile on AWS Graviton processors
Originally PyTorch used an eager mode where each PyTorch operation that forms the model is run independently as soon as it’s reached. PyTorch 2.0 introduced torch.compile to speed up PyTorch code over the default eager mode. In contrast to eager mode, the torch.compile pre-compiles the entire model into a single graph in a manner that’s optimal for […]

Identify idle endpoints in Amazon SageMaker
Amazon SageMaker is a machine learning (ML) platform designed to simplify the process of building, training, deploying, and managing ML models at scale. With a comprehensive suite of tools and services, SageMaker offers developers and data scientists the resources they need to accelerate the development and deployment of ML solutions. In today’s fast-paced technological landscape, […]

Improve visibility into Amazon Bedrock usage and performance with Amazon CloudWatch
In this blog post, we will share some of capabilities to help you get quick and easy visibility into Amazon Bedrock workloads in context of your broader application. We will use the contextual conversational assistant example in the Amazon Bedrock GitHub repository to provide examples of how you can customize these views to further enhance visibility, tailored to your use case. Specifically, we will describe how you can use the new automatic dashboard in Amazon CloudWatch to get a single pane of glass visibility into the usage and performance of Amazon Bedrock models and gain end-to-end visibility by customizing dashboards with widgets that provide visibility and insights into components and operations such as Retrieval Augmented Generation in your application.

Evaluate the reliability of Retrieval Augmented Generation applications using Amazon Bedrock
In this post, we show you how to evaluate the performance, trustworthiness, and potential biases of your RAG pipelines and applications on Amazon Bedrock. Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.

Connect to Amazon services using AWS PrivateLink in Amazon SageMaker
In this post, we present a solution for configuring SageMaker notebook instances to connect to Amazon Bedrock and other AWS services with the use of AWS PrivateLink and Amazon Elastic Compute Cloud (Amazon EC2) security groups.
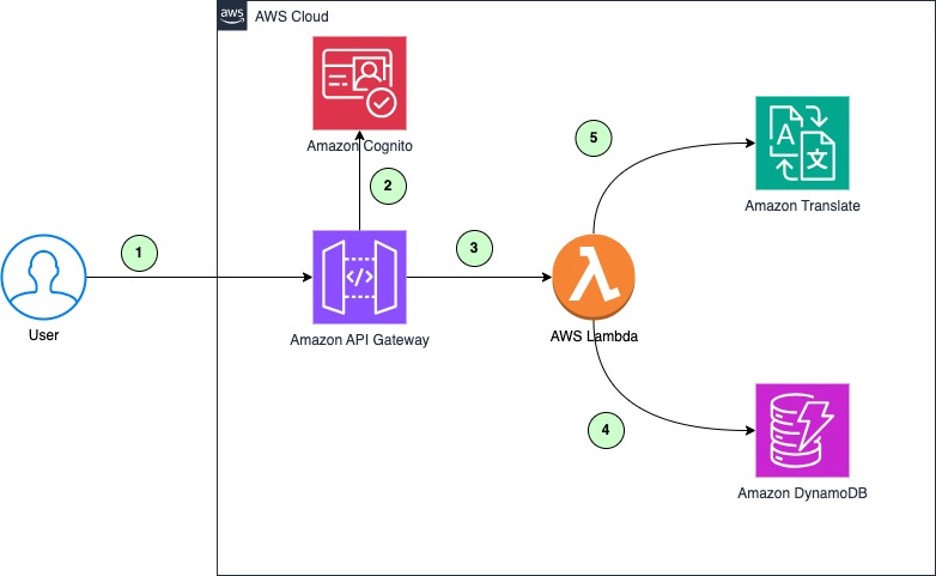
Maximize your Amazon Translate architecture using strategic caching layers
In this post, we explain how setting up a cache for frequently accessed translations can benefit organizations that need scalable, multi-language translation across large volumes of content. You’ll learn how to build a simple caching mechanism for Amazon Translate to accelerate turnaround times.

Build a custom UI for Amazon Q Business
Enable branded user experiences with specialized features like feedback handling and seamless conversation flows personalized for your use case and business needs.

Implementing Knowledge Bases for Amazon Bedrock in support of GDPR (right to be forgotten) requests
The General Data Protection Regulation (GDPR) right to be forgotten, also known as the right to erasure, gives individuals the right to request the deletion of their personally identifiable information (PII) data held by organizations. This means that individuals can ask companies to erase their personal data from their systems and from the systems of […]